7 Data Analytics Trends for 2022 That You Need to Watch Out For

Infrastructure
27.05.2022
9 min read
Share
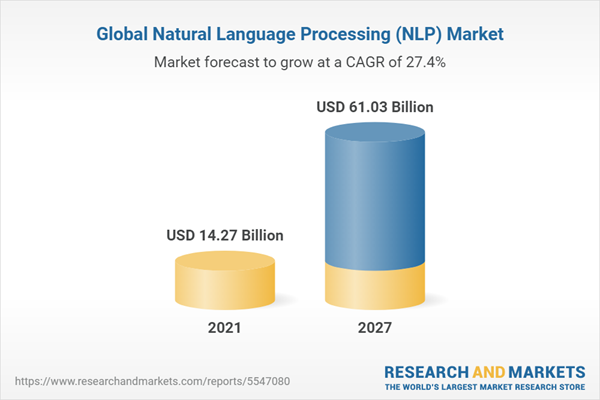
Over the past few years, data analytics has become a goldmine. The more data a company has, the more insight they have to make smarter decisions. With the data industry worth an estimated $274 billion in 2022, it’s no wonder big data is the driving force for the future.
The pandemic continues to drive business digital transformations. Applications have an improved capacity to interpret incoming data for its user. This means that the opportunities for business growth are endless.
Organizations embrace the cutting-edge data technology available to them. Data analytics continues to evolve, from big data to artificial intelligence (AI), data-driven models are in demand more than ever.
With the pandemic and its economic disruptions, businesses now realize they need to better use the data available to them. With data analytics traditionally used to assess ‘what happened?’ It is now used to predict ‘what will happen?’
With that in mind, let’s take a look at the top seven data analytics trends for 2022 and how they can benefit your business.
Smarter artificial intelligence
With the introduction of artificial intelligence (AI), organizations are experiencing a specialized change in business strategy. AI accelerates business decision making by automating processes that determine data analytics.
By developing training models and testing metrics in agile methodology, AI ensures rapid data insight without the need for data scientists. Organizations are utilizing AI algorithms to measure, predict, and interpret large amounts of data. Data refers to the market, customers, and online applications.
The pandemic and the rise of remote work have increased opportunities to track and measure data. Due to this rise in data availability, establishing a new data-driven culture was necessary. A culture that fuels investments via AI-based technologies produces intuitive data analytics.
AI systems work with both large and small data sets. The systems protect privacy, are adaptive, and provide a faster return on investment. The advancement of intuitive UIs in services such as metabase analytical services promotes accessibility and efficiency. Simply put, it’s never been easier to interpret data.
Edge computing
CTO of Kinetica, Nima Negahban, describes edge computing as ‘data analysis that takes place on a device in real-time.’ She goes on to say that ‘edge computing is about processing data locally, and cloud computing is about processing data in a data center or public cloud.’
Edge computing delivers data analytics technology closer to the physical asset. From wrist wearables to mobile traffic apps, worldwide spending on edge computing is expected to reach $176 billion in 2022.
To introduce edge computing into business systems, industries need to include IoT app development and other data transformation services.
By processing data storage closer to the devices that collect it, edge computing is more reliable. With real-time processing there is no issue of latency, it is also more cost-efficient than cloud-based storage.
Cloud-based data solutions
As data is being produced in large quantities, there will be an increasing shift towards cloud-based solutions. A database in the cloud involves labeling, cleaning, formatting, and collecting. It equates to a mammoth amount of storage for one location. This is where cloud-based platforms come into play.
The cloud opens the door for the next generation of data warehousing. With added accuracy and security in the form of an existing QA framework. New practices such as data mesh, data fabric, and Data Vault 2.0 have been intrinsically built via the cloud.
-
Data mesh - a holistic approach that allows data products connectivity across many domains. Enabling an information exchange without the need for storage.
-
Data fabric - architecture that enables data access in a distributed environment.
-
Data Vault 2.0 - based on the potential of the cloud, Data Vault 2.0 provides greater productivity. Driven by metadata for collaborative configuration and management of testing models.
Whilst a private cloud for your business can be costly, a hybrid cloud provides both private and public agility. A hybrid cloud approach offers companies the opportunity to switch between multiple cloud platforms. This is a more cost-effective approach for your business.
Data fabric
Due to our booming digital age, our interconnected ecosystem has become more complex than ever. Finding a solution to connect devices, applications, and data infrastructure formats is a constant challenge. Data fabric emerges as the solution.
Data fabric is a new answer to an old dilemma. With 73% of analytical data going unused, it has become essential for missing data to become discoverable. Data fabrics fuse data from internal silos and external data sources. This leads to the discovery of effective networks and business applications.
More companies are using data fabric architecture to produce more discoverable, pervasive, and reusable data from all environments. This includes private, public, and mulitcloud cloud systems.
Data fabric connects data from contrasting applications to identify new data relationships. It’s a form of referral software that enables rapid decision-making and cost-efficiency. Accelerating hybrid data integration ensures digital security and greater business value.
Data fabric is a technology that will become commonplace over the next few years.
Augmented analytics
Augmented analytics is a leading analytics concept that uses natural language processing (NLP), machine learning (ML), and AI. What used to be handled by a data scientist is now automated to offer economical data sharing and insight discovery.
Augmented analytics produces data integration from internal and external enterprises. Due to the specialist applications, the outcomes are more precise. NLP, ML, and AI ensure in-depth reports and forecasts, data processing, analytics, and visualization.
- Natural language processing - NLP provides computers with the ability to understand text and spoken words. It’s included in identifying patterns and trends in corporate operations. NLP is essential for tracking Twitter Analytics, understanding customer satisfaction, and smart assistants.
Machine learning - there is a growing use of data analytics and ML to predict what will happen in digital analytics and the best response to counter. Using ML to target specific customer needs, such as analyzing social media activity to determine what product they might buy.
- AI - AI helps make predictions more accurate, efficient, and cost-effective without the need for human intervention. AI will continue to be implemented in many different industries due to its unique possibilities.
 Machine learning - there is a growing use of data analytics and ML to predict what will happen in digital analytics and the best response to counter. Using ML to target specific customer needs, such as analyzing social media activity to determine what product they might buy.
Machine learning - there is a growing use of data analytics and ML to predict what will happen in digital analytics and the best response to counter. Using ML to target specific customer needs, such as analyzing social media activity to determine what product they might buy.With the introduction of all three, it has never been easier to measure, interpret, and predict results. Targeting specific customer behaviors reduces problems such as customers leaving their digital shopping cart abandoned and inefficient resources.
NLP, MI, and AI have the capabilities to assist business intelligence and aid business users.
Businesses are focussing on operational agility and resilience to recover from difficult market situations.
Automated machine learning
Applying ML models to real-world situations is known as automated machine learning (AutoML). ML is more user friendly when it is automated. It can create and deploy systems that even non-experts can master.
AutoML enhances monotonous workloads. Leaving human interaction free for more complemented questions (think of automation in call centers).
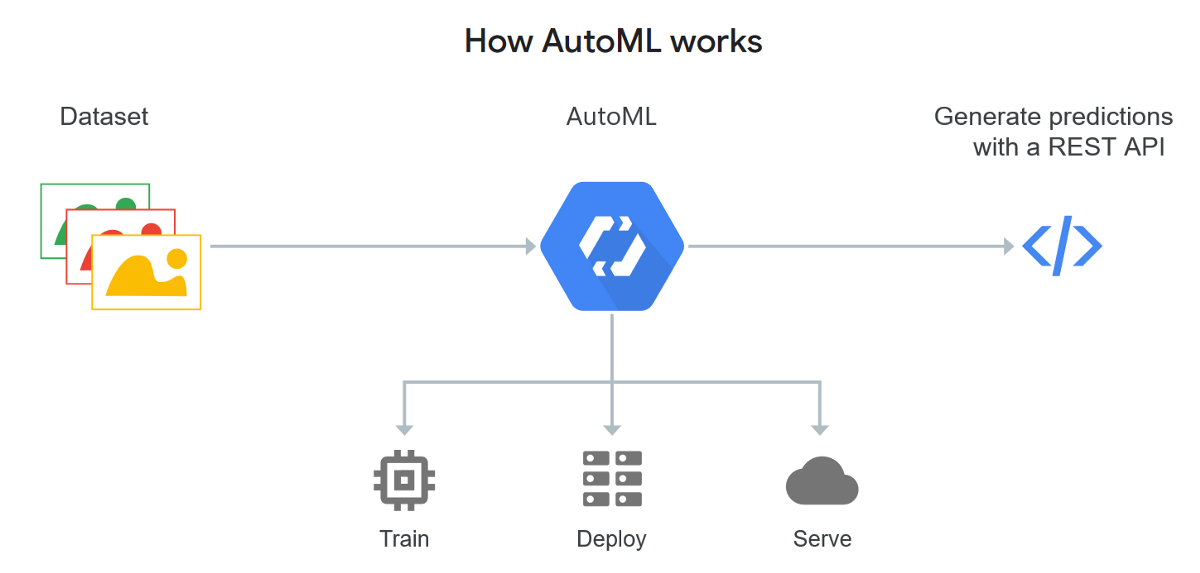
Businesses are counting on AutoML to increase data insight as end-users have direct access to these applications. As more users utilize this model, generating insight becomes easier and easier.
With the continuous release of machine learning tools, technical aspects of data science will become automated. This accelerates decision making by automating processes that data scientists would generally perform.
Much like how a mobile application is a must for small business development, AutoML is essential for rapid data insight. The more platforms that use it, the faster it becomes.
XOps
XOps has become an important fixture in business enterprise. It encompasses DataOps, ModelOps, AIOps, and PlatformOps, enabling automation of technology and processes. Making it a dominant combination of IT disciplines and strategic decision making when it comes to AI and machine learning (ML).
XOps data professionals can process defined goals that align with their business priorities. Its main focus is to enhance business operations as well as customer experience. Enhancing operations means enhanced security, which awards applications and offers advanced protection from DDoS attacks.
XOps strives to reduce duplication, ensuring more efficient and reliable data outcomes. Enabling XOps data and analytics allows the user to begin automation from the beginning rather than as an afterthought. It allows you to orchestrate your automating software in a way that meets measurable goals. Allowing more efficient data collection.
To cut a long story short
As data science continues to take the spotlight. Breakthroughs in future analytics continue to progress. Presently, data has never been more accessible, with companies able to collect, manage, analyze, and leverage data for future business intelligence.
Data analytics has become an essential part of business functionality. AI trends and data analysis provide valuable insight that improves business automation, accessibility, and intuition.
Organizations that successfully impose the above trends will be able to harness data strategically and efficiently. Tools such as automated machine learning and edge computing can improve customer algorithms via results and feedback.
Ensuring the process of data accumulation and evaluation is accessible, business actions have never been more necessary. Constantly improving analytics means businesses are constantly preparing for the future.
Author: Emily Rollwitz - Content Marketing Executive, Global App Testing
Emily Rollwitz is a Content Marketing Executive at Global App Testing, a remote and on-demand API automation testing tools company helping top app teams deliver high-quality software, anywhere in the world. She has 5 years of experience as a marketer, spearheading lead generation campaigns and events that propel top-notch brand performance. Handling marketing of various brands, Emily has also developed a great pulse in creating fresh and engaging content. She’s written for great websites like Airdroid and Shift4Shop. You can find her on LinkedIn.
Infrastructure
27.05.2022
9 min read
Share
Similar
Infrastructure
Top Alternatives to Speedtest for Checking Your Internet Speed
Now, when a huge amount of work time is spent online and the quality of video calls, streams, and online games directly depends on connection stability, regularly checking internet speed becomes a necessity.
We've tested popular services, selected the best ones, and are ready not only to review Speedtest alternatives but also to provide practical recommendations on when to use which service.
Let's examine everyday, professional, and specialized solutions for checking internet speed.
Speedcheck.org
Website: speedcheck.org
Features:
Detailed statistics: measures Download, Upload, Ping, and Jitter
Test history: saves previous results for comparison
Global servers: automatically selects the optimal server for testing
Pros:
Suitable for quick checks
Has advanced settings (server selection)
Cons:
Some features (like detailed analytics) are only available in the Pro version
Verdict: A convenient service with advanced capabilities, including test history and server selection. Suitable for users who need more detailed analytics, but some features are only available in the Pro version.
Fast.com
Website: fast.com
Features:
Instant test launch: measurement begins immediately upon opening the page
Focus on real streaming speed, as the service was created by Netflix
Minimalist interface without ads or unnecessary elements
Pros:
Very simple and fast test
Excellent for checking video streaming speed
Requires no settings
Cons:
Less technical data than competitors
No server selection or advanced statistics
Verdict: An ideal option when you need an instant and maximally simple check of actual download speed, especially for streaming. But for deep connection analysis, there may not be enough data.
SpeedOf.Me
Website: speedof.me
Features:
Simulates real web browsing load, providing a more "practical" test
Step-by-step speed graphs showing connection behavior dynamically
Pros:
High accuracy and realistic test results
Suitable for mobile devices
Clear graphs and reports
Cons:
Interface is slightly more complex than more minimalist services
Results may take longer to collect with weak connections
Verdict: A good option for users who want to see real speed behavior, not just final numbers. Suitable for technically savvy audiences.
TestMy.net
Website: testmy.net
Features:
Completely independent service, not affiliated with major providers
Allows testing download and upload separately and very accurately
Metrics are not averaged; you see real connection performance
Pros:
High accuracy with unstable internet
Extended set of tests (including automatic schedules)
Suitable for analyzing connection problems
Cons:
Less modern interface
Results are presented in fairly technical form
Verdict: An excellent tool for deep analysis of connection quality and identifying problems. Suitable for those who need accuracy and independence, not just basic numbers.
Google Speed Test
Available directly in Google search by querying "speed test" and clicking "Run Speed Test."
Features:
Launches without going to a separate site, right in search results
Provides basic metrics: Download, Upload, and Latency
Uses M-Lab infrastructure, an open platform supported by Google
Pros:
Maximally simple and fast access to the test
Reliable and stable results
No ads or unnecessary elements
Cons:
Minimal data set, no advanced statistics
No ability to select a server
No test history
Verdict: An excellent option for quick and reliable speed checks right in search, without transitions or settings. But the tool remains basic; for detailed analysis, it's better to choose specialized services.
Cloudflare Speed Test
Website: speed.cloudflare.com
Features:
Checks internet speed using its own high-performance CDN network
Conducts comprehensive testing of download, upload, and ping
Displays information about the route, protocol used, and IPv6 status
Pros:
Modern technologies and wide range of data about connection quality
Cons:
The service is optimized for modern high-speed connections, which may reduce measurement accuracy for users with low connection speeds
Verdict: The most advanced professional tool for comprehensive internet connection diagnostics.
M-Lab
Website: speed.measurementlab.net
Features:
Open research project designed to collect anonymous data about internet speeds worldwide
Statistics are provided publicly and available for analysis
Pros:
Scientifically grounded approach. All tests are conducted according to a single standard, and algorithms are openly available. You can verify that the service provides honest results with no "tweaking."
Low probability of errors. Uses NDT, Neubot, and other algorithms that make minimal errors.
Cons:
Less convenient for regular users due to outdated interface
Verdict: A useful tool for researchers and large organizations interested in studying real internet speeds.
GameServerPING
Website: gameserverping.com/speedtest/
Features:
A gamer-oriented service where you can conduct both regular internet speed checks and test latency (ping) between your device and selected game servers ("Game Pings" tab)
Pros:
Convenient for players who care about low ping
Cons:
Narrowly focused on the gaming industry, less convenient for regular users
Verdict: A good choice for gamers. The service helps determine internet speed and select a game server with minimal latency.
Conclusion
After testing the most popular alternatives to Speedtest by Ookla, we can highlight the following:
For quick everyday checks
Fast.com, Google Speed Test, and SpeedOf.Me are the most convenient and reliable options.
Fast.com is perfect for instant streaming-oriented measurements, Google Speed Test is ideal when you need a quick check right from search results, and SpeedOf.Me provides a more realistic browser-based test suitable for both desktop and mobile use.
For professional analysis
Cloudflare Speed Test remains the strongest choice for in-depth diagnostics, including routing data, protocol insights, and IPv6 support.
M-Lab is useful for researchers and organizations that need scientifically grounded and openly verifiable measurements.
For gamers
GameServerPING is the best way to measure latency to specific game servers and choose the optimal region for online play.
10 December 2025 · 5 min to read
Infrastructure
IT Cost Optimization: Reducing Infrastructure Expenses Without Compromising Performance
Infrastructure costs grow imperceptibly. Typically, teams start by renting a couple of virtual machines, a database, and storage. In this setup, the system works smoothly, and the team focuses on the product. But as the project grows, the infrastructure "sprawls": one provider for servers, another for databases, a third for file storage. Test environments, temporary instances, and "just in case" disks appear. As a result, the budget increases not because of new features, but because of numerous disparate solutions.
The more complex the architecture becomes, the harder it is to control costs. The team spends time not on the product but on maintaining infrastructure, trying to maintain a balance between performance and budget.
In this article, we'll explore how to approach cloud infrastructure rationally: what to optimize first, what we often overpay for, how to avoid fragmentation, and how to make the team’s life easier by consolidating key services on a single platform.
Infrastructure Audit: What to Check First
Cloud cost optimization doesn't start with cuts, but with transparency.
Companies often try to save money without understanding where exactly the money is going. Therefore, the first step is to conduct an audit of the current infrastructure and identify inefficient or unused resources.
To conduct a good audit, companies usually invite cloud architects or DevOps engineers. They typically look for problems according to the following plan.
1. Server Load
The most common cause of unnecessary expenses is virtual machines launched "with reserve." If CPU and RAM consistently work at 10-20%, it means the configuration is excessive. This is especially noticeable in projects that scaled in a hurry and where resources were expanded just in case.
It's useful to evaluate average and peak CPU load, the amount of RAM used, disk subsystem metrics like IOPS and latency, as well as network traffic dynamics—this provides a holistic understanding of how efficiently servers are working.
In this case, even a small configuration adjustment can reduce costs without loss of stability.
2. Idle Resources
Over time, infrastructure accumulates test servers, temporary databases, forgotten disks, and old snapshots. This is the invisible but constant expense item.
Pay attention to virtual machines without traffic, disconnected disks, outdated backups, and test instances that were once launched temporarily but remained in the infrastructure.
These are the elements that should be optimized in the first hours of the audit.
3. Databases
Databases are one of the most expensive infrastructure components. Here, it's important to look not only at the number of resources, but also at the actual load. Often large clusters are deployed simply because "it's safer that way."
It's useful to check query frequency, number of active connections, disk load, and the actual volume of storage used—these indicators will help quickly determine whether the current cluster size is justified.
Also make sure databases aren't duplicated for different environments.
4. Logs and Storage
Logs and media files can take up more and more space if they're not moved to object storage. Storing all this on server disks is unjustifiably expensive.
Evaluate the volume of logs, their storage and rotation policy, media archive size, as well as backup location and frequency—this makes it easier to understand whether data is accumulating where it shouldn't be.
Optimizing Compute Resources
After the audit, it becomes clear which servers the project really needs and which work inefficiently. The next step is to select configurations so that they correspond to the actual load and grow with the product, rather than exceeding it several times over.
The main principle here is that resources should not be "more than needed," but "exactly as much as needed now." If the load increases, in the cloud it's easier to add resources to an existing server or add a new instance than to constantly maintain a reserve for peak loads. This approach allows you to reduce costs without risk to stability.
It's important to correctly choose machine types for different tasks. For example, standard VMs are most often suitable for web applications, GPU-optimized servers for analytical or ML workloads, and separate disk configurations for services with high read and write intensity.
Another way to optimize cloud computing costs is not to scale up one large server, but to distribute the load across several smaller VMs using a load balancer. It receives incoming traffic and directs it to available instances so that no single machine becomes a "bottleneck." This approach scales smoothly: if the project grows, you simply add a new VM to the pool, and the balancer immediately takes it into account when distributing requests. In Hostman, the load balancer is built into the ecosystem and easily connects to any set of servers.
When the load increases, the team spins up new instances; when it decreases, they shut down excess ones, thus adapting infrastructure to real conditions, not theoretical peaks.
Ultimately, compute resource optimization is about flexibility. Resources scale with the product, and the budget is spent on what actually brings value, not on excessive configurations.
Optimizing Database Operations
After the audit, it becomes clear which database instances are actually used. The next step is to build a data storage architecture that is not only reliable but also economically justified. In working with databases, this largely depends on the correct choice of technology and operating model.
Choosing a Database Engine
Different types of loads require different approaches. Transactional systems—online stores, CRM, payment services—work best with classic OLTP (Online Transaction Processing) solutions like PostgreSQL or MySQL, where write speed and operation predictability are important. If we're talking about documents, user content, or flexible data schemas, MongoDB is more convenient. And analytical tasks—reports, metrics, aggregates over millions of rows—are better suited to OLAP (Online Analytical Processing) solutions like ClickHouse.
The right database choice immediately reduces costs: the project doesn't overpay for resources that don't fit the load type and doesn't waste time on complex workarounds.
Why DBaaS Saves Budget
Even a perfectly selected database becomes expensive if you deploy and maintain it yourself. Administration, updates, replication, backup, fault tolerance—all this takes a lot of time and requires competencies that are difficult and expensive for startups or small teams to maintain.
The DBaaS format removes most of these tasks. The platform provides SLA, monitors cluster fault tolerance, updates versions, manages backups, and provides clear scaling tools.
In addition, there are no hidden costs: the database works within a stable platform, and the provider takes on all infrastructure tasks.
Horizontal Scaling Without Overpaying
When the load grows, it doesn't always make sense to strengthen the main node. In managed databases, it's easier and more reliable to scale the system by distributing different types of load across separate services: leave the transactional part in the OLTP database and move analytical calculations to a separate OLAP cluster like ClickHouse. This approach reduces pressure on the main node and saves the application from slowdowns due to heavy queries. Within DBaaS, this is usually the most predictable and accessible scaling scenario—without manual sharding and complex replica configuration.
This approach reduces pressure on the master node and allows avoiding a sharp budget jump. The system scales gradually: as the load grows, replicas are added rather than expensive "monolithic" server configurations.
How to Save on Databases in Hostman
Managed databases combine the convenience of DBaaS and configuration flexibility. Clusters are created in minutes, and configuration is selected based on project needs—without excessive reserve. When the load grows, you can increase the configuration. Scaling happens quickly and without complex migrations, and payment is only for actual resource consumption.
This approach helps keep the budget under control and not overpay for capacity that is only partially used.
File and Log Storage: Transition to Object Storage
When a project grows, file volume inevitably increases: media, exports, backups, temporary data, system artifacts. In the early stages, they're often stored directly on the server disk—this seems like the simplest and fastest solution. But as the application grows, this approach begins to noticeably increase costs and complicate infrastructure operations.
Why It's Unprofitable to Store Files on Server Disks
The main disadvantage is tying data to a specific machine. If a server needs to be replaced, expanded, or moved, files have to be copied manually. Scaling also becomes a problem: the more data stored, the faster disk costs grow, which are always more expensive than cloud storage.
Another complexity is fault tolerance. If something happens to the server, files are at risk. To avoid this, you have to configure disk duplication or external backups—and that's additional costs and time.
How Object Storage Reduces Costs
S3 object storage removes most of these limitations. Data is stored not on a specific server, but in a distributed system where each file becomes a separate object with a unique key. Such storage is cheaper, more reliable, and doesn't depend on specific applications or VMs.
The economic effect is immediately noticeable:
Volume can be increased without migrations and downtime
Files are automatically distributed across nodes, ensuring fault tolerance
No need to pay for disk resources of individual servers
Easier to plan the budget—storage cost is predictable and doesn't depend on machine configuration
Where to Use S3 in Applications
S3 is convenient to use where data should be accessible from multiple parts of the system or where scaling is important:
Images and user content
Web application static files
Archives and exported data
Backups
CI/CD artifacts
Machine logs that then undergo processing
This separation reduces the load on application servers and gives infrastructure more flexibility.
S3 Features in Hostman
In Hostman, object storage integrates with the rest of the platform infrastructure and works on the S3-compatible API model, which simplifies the transition from other solutions.
Lifecycle policies are also supported: you can automatically delete old objects, move them to cheaper storage classes, or limit the lifespan of temporary files. This helps optimize costs without manual intervention.
Integration with virtual servers and Kubernetes services makes S3 a convenient architecture element: the application can scale freely, and data remains centralized and reliably stored.
Containerization: How to Ensure Stability and Reduce Operating Costs
Containerization has become a basic tool for projects where it's important to quickly deploy environments, predictably update services, and flexibly work with load.
In addition to development convenience, it also provides tangible savings: a properly configured container architecture allows using infrastructure much more efficiently than the classic "one server—one application" model.
Why Containers Are Cheaper to Operate
Unlike virtual machines, containers start faster, take up fewer resources, and allow placing multiple services on the same node without risks to stability.
The team stops maintaining multiple separate servers "for every little thing"—all services are packaged in containers and distributed across nodes so that resources are used as densely as possible. This reduces infrastructure costs and decreases the number of idle machines.
Savings Through Kubernetes
Kubernetes has a particularly noticeable impact on the budget. It automatically adjusts the number of containers to the load: if traffic has grown, it spins up new instances; if it has fallen, it stops excess ones. The project pays only for actual resource usage, not for reserves maintained for peak values.
In addition, Kubernetes simplifies fault tolerance. Applications are distributed among different servers, and the failure of one node doesn't lead to downtime. This reduces costs associated with failures and decreases the need for expensive backup servers.
Less Manual Work, Lower Costs
In container architecture, updates, rollbacks, test environment deployments, and scaling turn into automated processes. The team spends less time on administration, which means less money on operational tasks.
Kubernetes also allows running environments for the duration of tasks. For example, spinning up environments for CI/CD, load testing, or preview—and automatically deleting them after work is completed.
Kubernetes in Hostman
Kubernetes is provided as a fully managed service (KaaS). The platform handles updating master nodes, network configuration, fault tolerance, and the overall state of the cluster. The team works only with nodes and containers, avoiding routine DevOps tasks.
Nodes can be added or removed literally in minutes. This is convenient when the load fluctuates: infrastructure quickly expands or contracts, and the budget remains predictable.
Integration with object storage, network services, and managed databases makes Kubernetes part of a unified architecture where each element scales independently and without unnecessary costs.
Network and Security Without Unnecessary Costs
When designing network architecture, it's easy to make mistakes that not only reduce system resilience but also increase the budget.
How Improper Network Organization Increases Budget
Even small flaws in network configuration can cause a noticeable financial drain. For example, if an internal service is accessible via a public IP, traffic starts passing through an external channel, which increases latency and data transfer costs. A similar situation arises when the database and backend are on different servers but not connected by a private network. Some cloud providers might meter such traffic, which can become an unexpected expense. In Hostman, data transfers are free, but a private network still offers advantages: higher transfer speeds, reduced security risks, and the ability to avoid unnecessary public IPs.
Without private networks, security also becomes more complicated. To restrict access, you have to build additional firewall rules and load balancers, and each such solution costs money, be it in the form of resources or human hours.
Savings Start With Network Structure
In a rational network organization, each component operates in its proper zone and routes traffic to where it's safe and free. Private networks allow isolating sensitive services (databases, internal APIs, queues) and completely removing them from public space. This reduces the attack surface, decreases the number of required firewall rules, and eliminates costs for unnecessary traffic.
Floating IPs help save on fault tolerance: instead of reserving a powerful server, it's enough to prepare for quickly transferring the address to another VM. Switching happens almost instantly, and the service remains available for users. This scheme allows ensuring resilience without the expense of duplicate configurations.
Reducing Costs Through Fault Tolerance
Improperly configured networks often cause downtime, and downtime means direct losses. Proper load distribution, load balancers, and private routes allow avoiding a situation where one server becomes a bottleneck and takes the application out of service.
A separate point is DDoS protection. This is not only about security but also about economics: during an attack, the service can become unavailable, and unavailability almost always means losing customers, orders, and reputation. DDoS protection cuts off malicious traffic before it enters the infrastructure, reducing server load and preventing downtime that easily turns into tangible losses.
Automation: How to Reduce Operating Costs
Even perfectly selected infrastructure can remain expensive if managed manually. Creating test environments, updating configurations, scaling, backup rotation, server management—all this turns into a long chain of manual actions that take hours of work and lead to errors. Automation reduces maintenance costs through repeatability, predictability, and the elimination of human error.
Why Manual Infrastructure Is More Expensive
Manual operations always mean:
Risk of forgetting to delete a temporary environment
Inconsistent settings between servers
Unpredictable downtime due to errors
Developer time spent on routine instead of the product
These are direct and indirect costs that easily hide in the process but noticeably increase the final budget.
Which Processes Are Most Profitable to Automate
From a savings perspective, three areas provide the most benefit:
Environment Deployment. Quick creation of environments for development, testing, preview, and load tests. The environment is spun up automatically, works for the required time, and is deleted when no longer needed.
Infrastructure Scaling. Load peaks can be handled automatically: spin up additional resources based on metrics, then shut them down. This way, you pay only for the peak, not for maintaining a constant reserve.
Unified Configuration Description. When the environment is described as code, it can be reproduced at any stage, from development to production. This reduces the number of errors and eliminates "manual magic."
Infrastructure as Code: An Economic Tool
IaC solves the main problem of the manual approach: unpredictability. Configuration is stored in Git, changes are tracked, environments are created identically.
The team spends less time on maintenance, plans the budget more easily, and responds to load changes faster. As a result, operating costs are reduced, and infrastructure becomes more transparent and manageable.
Hostman Tools for Automation
Hostman provides a set of tools that help build automation around the entire infrastructure:
Public API. Automatic management of servers, networks, databases, and storage.
Terraform provider, for a complete IaC approach: the entire infrastructure is described as code.
cloud-init. Allows deploying servers immediately with preconfigured settings, users, and packages.
Together, they create infrastructure that can be spun up, modified, and scaled automatically, without unnecessary actions and costs. This is especially important for teams that need to move quickly but without constant overspending.
Conclusion
Optimizing infrastructure costs is about building a mature approach to working with resources. At each stage, it seems that costs are quite justified, but in total they turn into a tangible burden on the budget—especially if the team scales quickly.
To keep spending under control, it's important not to cut resources blindly, but to understand how infrastructure works and which elements the product really needs here and now. An audit helps find inefficient parts of the system. Correct work with computing power and databases reduces costs without loss of performance. Transition to object storage makes the architecture more flexible and reliable. Containerization and Kubernetes remove dependence on manual actions. Automation frees the team from routine and prevents errors that cost money. Proper network organization increases resilience—and simultaneously reduces costs.
For many projects, it makes sense to rent a VPS instead of investing in dedicated hardware. VPS hosting for rent gives you predictable performance, root access, and the freedom to scale resources as your workload grows—without overpaying upfront.
Rational architecture is not about saving for saving's sake. It's about resilience, speed, and the project's ability to grow without unnecessary technical and financial barriers. And the earlier the team transitions from chaotic resource accumulation to a thoughtful management model, the easier it will be to scale the product and budget together.
09 December 2025 · 16 min to read
Infrastructure
Apache Kafka and Real-Time Data Stream Processing
Apache Kafka is a high-performance server-based message broker capable of processing enormous volumes of events, measured in millions per second. Kafka's distinctive features include exceptional fault tolerance, the ability to store data for extended periods, and ease of infrastructure expansion through the simple addition of new nodes. The project's development began within LinkedIn, and in 2011, it was transferred to the Apache Software Foundation. Today, Kafka is widely used by leading global companies to build scalable, reliable data transmission infrastructure and has become the de facto industry standard for stream processing.
Kafka solves a key problem: ensuring stable transmission and processing of streaming data between services in real time. As a distributed broker, it operates on a cluster of servers that simultaneously receive, store, and process messages. This architecture allows Kafka to achieve high throughput, maintain operability during failures, and ensure minimal latency even with many connected data sources. It also supports data replication and load distribution across partitions, making the system extremely resilient and scalable.
Kafka is written in Scala and Java but supports clients in numerous languages, including Python, Go, C#, JavaScript, and others, allowing integration into virtually any modern infrastructure and use in projects of varying complexity and focus.
How the Technology Works
To work effectively with Kafka, you first need to understand its structure and core concepts. The system's main logic relies on the following components:
Messages: Information enters Kafka as individual events, each representing a message.
Topics: All messages are grouped by topics. A topic is a logical category or queue that unites data by a specific characteristic.
Producers: These are programs or services that send messages to a specific topic. Producers are responsible for generating and transmitting data into the Kafka system.
Consumers: Components that connect to a specific topic and extract published messages. To improve efficiency, consumers are often organized into consumer groups, thereby distributing the load among different instances and allowing better management of parallel processing of large data volumes. This division significantly improves overall system performance and reliability.
Partitions: Any topic can be divided into partitions, enabling horizontal system scaling and increased performance.
Brokers: Servers united in a Kafka cluster perform functions of storing, processing, and managing messages.
The component interaction process looks as follows:
The producer sends a message to a specified topic.
The message is added to the end of one of the topic's partitions and receives its sequential number (offset).
A consumer belonging to a specific group subscribes to the topic and reads messages from partitions assigned to it, starting from the required offset. Each consumer independently manages its offset, allowing messages to be re-read when necessary.
Thus, Kafka acts as a powerful message delivery mechanism, ensuring high throughput, reliability, and fault tolerance.
Since Kafka stores data as a distributed log, messages remain available for re-reading, unlike many queue-oriented systems.
Key Principles
Append-only log: messages are not modified/deleted (by default), they are simply added. This simplifies storage and replay.
Partition division for speed: one topic is split into parts, and Kafka can process them in parallel. Thanks to this, it scales easily.
Guaranteed order within partition: consumers read messages in the order they were written to the partition. However, there is no complete global ordering across the entire topic if there are multiple partitions.
Messages can be re-read: a consumer can "rewind" at any time and re-read needed data if it's still stored in Kafka.
Stable cluster operation: Kafka functions as a collection of servers capable of automatically redirecting load to backup nodes in case of broker failure.
Why Major Companies Choose Apache Kafka
There are several key reasons why large organizations choose Kafka:
Scalability
Kafka easily handles large data streams without losing performance. Thanks to the distributed architecture and message replication support, the system can be expanded simply by adding new brokers to the cluster.
High Performance
The system can process millions of messages per second even under high load. This level of performance is achieved through asynchronous data sending by producers and efficient reading mechanisms by consumers.
Reliability and Resilience
Message replication among multiple brokers ensures data safety even when part of the infrastructure fails. Messages are stored sequentially on disk for extended periods, minimizing the risk of their loss.
Log Model and Data Replay Capability
Unlike standard message queues where data disappears after reading, Kafka stores messages for the required period and allows their repeated reading.
Ecosystem Support and Maturity
Kafka has a broad ecosystem: it supports connectors (Kafka Connect), stream processing (Kafka Streams), and integrations with analytical and Big Data systems.
Open Source
Kafka is distributed under the free Apache license. This provides numerous advantages: a huge amount of official and unofficial documentation, tutorials, and reviews; a large number of third-party extensions and patches improving basic functionality; and the ability to flexibly adapt the system to specific project needs.
Why Use Apache Kafka?
Kafka is used where real-time data processing is necessary. The platform enables development of resilient and easily scalable architectures that efficiently process large volumes of information and maintain stable operation even under significant loads.
Stream Data Processing
When an application produces a large volume of messages in real time, Kafka ensures optimal management of such streams. The platform guarantees strict message delivery sequence and the ability to reprocess them, which is a key factor for implementing complex business processes.
System Integration
For connecting multiple heterogeneous services and applications, Kafka serves as a universal intermediary, allowing data transmission between them. This simplifies building microservice architecture, where each component can independently work with event streams while remaining synchronized with others.
Data Collection and Transmission for Monitoring
Kafka enables centralized collection of logs, metrics, and events from various sources, which are then analyzed by monitoring and visualization tools. This facilitates problem detection, system state control, and real-time reporting.
Real-Time Data Processing
Through integration with stream analytics systems (such as Spark, Flink, Kafka Streams), Kafka enables creation of solutions for operational analysis and rapid response to incoming data. This allows for timely informed decision-making, formation of interactive monitoring dashboards, and instant response to emerging events, which is critically important for applications in finance, marketing, and Internet of Things (IoT).
Real-Time Data Analysis
Through interaction with stream analytics tools (for example, Spark, Flink, Kafka Streams), Kafka becomes the foundation for developing solutions ensuring fast processing and analysis of incoming data. This functionality enables timely important management decisions, visualization of indicators in convenient interactive dashboards, and instant response to changing situations, which is extremely relevant for financial sector companies, marketers, and IoT solution developers.
Use Case Examples
Here are several possible application scenarios:
Web platforms: any user action (view, click, like) is sent to Kafka, and then these events are processed by analytics, recommendation system, or notification service.
Fintech: a transaction creates a "payment completed" event, which the anti-fraud service immediately receives. If suspicious, it can initiate a block and pass data further.
IoT devices: thousands of sensors send readings (temperature, humidity) to Kafka, where they are processed by streaming algorithms (for example, for anomaly detection), and then notifications are sent to operators.
Microservices: services exchange events ("order created," "item packed," etc.) through Kafka without calling each other directly.
Log aggregation: multiple services send logs to Kafka, from where analytics systems, SIEM, or centralized processing systems retrieve them.
Logistics: tracking delivery statuses or real-time route distribution.
Advertising: collection and analysis of user events for personalization and marketing analytics.
These examples demonstrate Kafka's flexibility and its application in various areas.
When Kafka Is Not Suitable
It's important to understand the limitations and situations when Kafka is not the optimal choice. Several points:
If the data volume is small (for example, several thousand messages per day) and the system is simple, implementing Kafka may be excessive. For low traffic, simple queues like RabbitMQ are better.
If you need to make complex queries with table joins, aggregations, or store data for very long periods with arbitrary access, it's better to use a regular database.
If full ACID transactions are important (for example, for banking operations with guaranteed integrity and relationships between tables), Kafka doesn't replace a regular database.
If data hardly changes and doesn't need to be quickly transmitted between systems, Kafka will be excessive. Simple storage in a database or file may be sufficient.
Kafka's Differences from Traditional Databases
Traditional databases (SQL and NoSQL) are oriented toward storing structured information and performing fast retrieval operations. Their architecture is optimized for reliable data storage and efficient extraction of specific records on demand.
In turn, Kafka is designed to solve different tasks:
Working with streaming data: Kafka focuses on managing continuous data streams, while traditional database management systems are designed primarily for processing static information arrays.
Parallelism and scaling: Kafka scales horizontally through partitions and brokers, and is designed for very large stream data volumes. Databases (especially relational) often scale vertically or with horizontal scaling limitations.
Ordering and stream: Kafka guarantees order within a partition and allows subscribers to read from different positions, jump back, and replay.
Latency and throughput: Kafka is designed to provide minimal delays while simultaneously processing enormous volumes of events.
Example Simple Python Application for Working with Kafka
If Kafka is not yet installed, the easiest way to "experiment" with it is to install it via Docker. For this, it's sufficient to create a docker-compose.yml file with minimal configuration:
version: "3"
services:
broker:
image: apache/kafka:latest
container_name: broker
ports:
- "9092:9092"
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: broker,controller
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092,CONTROLLER://0.0.0.0:9093
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@localhost:9093
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_NUM_PARTITIONS: 3
Run:
docker compose up -d
Running Kafka in the Cloud
In addition to local deployment via Docker, Kafka can be run in the cloud. This eliminates unnecessary complexity and saves time.
In Hostman, you can create a ready Kafka instance in just a few minutes: simply choose the region and configuration, and the installation and setup happen automatically.
The cloud platform provides high performance, stability, and technical support, so you can focus on development and growth of your project without being distracted by infrastructure.
Try Hostman and experience the convenience of working with reliable and fast cloud hosting.
Python Scripts for Demonstration
Below are examples of Producer and Consumer in Python (using the kafka-python library), the first script writes messages to a topic and the other reads.
First, install the Python library:
pip install kafka-python
producer.py
This code sends five messages to the test-topic theme.
from kafka import KafkaProducer
import json
import time
# Create Kafka producer and specify broker address
# value_serializer converts Python objects to JSON bytes
producer = KafkaProducer(
bootstrap_servers="localhost:9092",
value_serializer=lambda v: json.dumps(v).encode("utf-8"),
)
# Send 5 messages in succession
for i in range(5):
data = {"Message": i} # Form data
producer.send("test-topic", data) # Asynchronous send to Kafka
print(f"Sent: {data}") # Log to console
time.sleep(1) # Pause 1 second between sends
# Wait for all messages to be sent
producer.flush()
consumer.py
This Consumer reads messages from the theme, starting from the beginning.
from kafka import KafkaConsumer
import json
# Create Kafka Consumer and subscribe to "test-topic"
consumer = KafkaConsumer(
"test-topic", # Topic we're listening to
bootstrap_servers="localhost:9092", # Kafka broker address
auto_offset_reset="earliest", # Read messages from the very beginning if no saved offset
group_id="test-group", # Consumer group (for balancing)
value_deserializer=lambda v: json.loads(v.decode("utf-8")), # Convert bytes back to JSON
)
print("Waiting for messages...")
# Infinite loop—listen to topic and process messages
for message in consumer:
print("Received:", message.value) # Output message content
These two small scripts demonstrate basic operations with Kafka: publishing and receiving messages.
Conclusion
Apache Kafka is an effective tool for building architectures where key factors are event processing, streaming data, high performance, fault tolerance, and latency minimization. It is not a universal replacement for databases but excellently complements them in scenarios where classic solutions cannot cope. With proper architecture, Kafka enables building flexible, responsive systems.
When choosing Kafka, it's important to evaluate requirements: data volume, speed, architecture, integrations, ability to manage the cluster. If the system is simple and loads are small—perhaps it's easier to choose a simpler tool. But if the load is large, events flow continuously, and a scalable solution is required, Kafka can become the foundation.
Despite certain complexity in setup and maintenance, Kafka has proven its effectiveness in numerous large projects where high speed, reliability, and working with event streams are important.
08 December 2025 · 12 min to read
Do you have questions,
comments, or concerns?
Our professionals are available to assist you at any moment,
whether you need help or are just unsure of where to start.
whether you need help or are just unsure of where to start.
