What Are Databases? 3 Most Popular Databases That Suit You
Have a website or a webapp with a lot of user data? Want to create a database to store it? We’ll tell you what a database in web hosting is, what sql database is and how to create a database for your site or app.
A database is an organized collection of structured information, or data, typically stored electronically in a computer system. Databases (DBs) are extensively used by developers and webmasters across industries and projects.
This article will tell you everything you need to know about how to use databases effectively in your projects, including important best practices for maintaining them.
What is a database? Copy link
In techie-speak, “A database is a sum total of data that is organized in accordance with formal design and modeling techniques.”
But nobody speaks like that (except engineers), so let’s break it down into something we humans can digest.
There are two ways to understand what databases are and how they work:
-
In “human” terms:
Imagine a massive pile of documents and files stored inside a library. You’ve got a librarian who knows exactly where every scrap of paper is, and can fetch it for you in a jiffy. The “library” is a database. The “librarian” is the programming language that manages the whole thing. -
In “technical” terms:
Let’s say you have an app or a website. All of its data (logins, passwords, digital shopping carts, lists of liked and bookmarked posts, documents created by users, etc) is saved and organized inside your database. Using a special programming language (more on that later) to communicate with your database, you can analyze and process the data as required.
What is database hosting and why should you use one? Copy link
Hosting is a remote computer (called a “server”) where website and application files (including the database) are stored.
If you were to store your app or website on your own computer, users would only be able to access it while your computer is turned on and connected to the internet. Moreover, it would be vulnerable to attack from external sources.
Hosting your app or website on a remote server, makes it possible to have it accessible at all times. The hosting server also provides a safer environment as well as a better performance due to its dedicated setup.
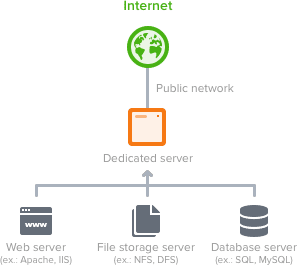
If you’re running a service that handles a lot of media (like Apple Music or Hulu), or an application with a large amount of information that needs to be synchronized between two or more devices (like Evernote), you will need to rent a web hosted database. But it’s perfectly acceptable to use databases on any type of website if it serves the right purpose for webmasters and helps to manage resources efficiently.
Do you need a database for a website or app? Copy link
A web hosted database is useful regardless of whether you’re running a website or a mobile application. If you’re working with user data and you want to store it, it is sensible to adopt a database, because it makes it more practical to manage, structure, control, analyze and process files.
In some cases where you’re running simple applications such as a basic to-do manager with local storage, or a modest website, saving files on a server harddrive might be enough. But as soon as the project begins to expand, you’ll find yourself outgrowing this solution very quickly.
What is an SQL database and how does it work? Copy link
SQL (sometimes pronounced “sequel”) stands for "Structured Query Language" — a programming language of "structured queries" that is used to efficiently save, search, update and extract database elements.
Let's use a simple database as an example — a list of movies available in the cinema.
In this case, our database will be a large table containing elements such as movie genre, actors, directors, and so on. The data will be presented in an array of columns and rows.
Let’s say one of the rows contains all the details about a certain movie. If you wanted to find a comedy with Brad Pitt, you would use a special SQL command (query) to filter out rows with the required data.
The same goes for any other type of table. You can use an SQL database to filter out goods that are on sale, or place user-made notes in specific directories, etc. That's what an SQL database is for.
What are the most popular SQL databases? Copy link
There are many types of SQL databases. Some popular ones include MySQL, Microsoft Access, MongoDB, and PostgreSQL. But there are hundreds to choose from.
In this section, we’ll be reviewing three of the best SQL DBs, based on their popularity among users.
What is MS SQL database? Copy link
MS SQL (also called “MS SQL Server Database”) is a relational database — a type of database that stores and provides access to data points that are related to one another.
The MS abbreviation in the name stands for “Microsoft”, because MS SQL was developed by the creators of the Windows operating system.
MS SQL Server Database combines the Microsoft Access proprietary database backend platform, and an application with a graphical user interface. This makes it possible to manipulate any type of information stored inside the rows and tables of the database.
Is MS SQL Database a good fit for you?
Microsoft Access Database is often touted as the best DB-engine for developers who favor the Microsoft ecosystem. It is a well-adapted product for Windows servers that integrates almost flawlessly with other Microsoft applications.
It is a commercial product, but the free Developer’s Edition offers many useful features. Microsoft Access backup and recovery processes are super smooth, so any webmaster or system engineer can use it.
It also boasts amazing on-demand support and an extended range of enterprise features.
What is MySQL Database? Copy link
MySQL is one of the most popular DB-engines, because it is open-source and free. The necessity of building a website with a crowded user base has led developers and webmasters to adapt DB-engines much more frequently.
In a span of just a few years, storing data in separate tables has become an industry standard. Everyone needs a database now, and MySQL is an excellent candidate because it is feature-rich, free, and doesn’t make webmasters deal with unnecessary enterprise bureaucracy.
More importantly, creating MySQL databases is a breeze compared to some of the cumbersome processes of some of its competitors. Additionally, most web hosting platforms support MySQL databases right out of the box.
Is MySQL Database a good fit for you?
MySQL has two main advantages:
-
Simplicity. Even non-professionals can swiftly get into the basics of this DB engine and create their first database. Moreover, the Internet is overflowing with information and tutorials for MySQL.
-
No cost. As opposed to Oracle and Microsoft Access, MySQL is free to use. You can use it to service your tiny, non-profit projects with a fully-functional DB-engine.
That said, MySQL has its downsides.
-
It has certain limitations when compared to Microsoft Access or Oracle, especially when working with unstructured data.
-
It has a hard time processing complex business logic efficiently.
-
It is less reliable, and its performance suffers in high-concurrency processes.
What is Oracle database? Copy link
Oracle is the most popular relational database on the market. It is the first-ever DB-engine created for an enterprise setup. Additionally, Oracle was the first company to release the commercial version of Structured Query Language.
The Oracle product stands out due to its unique features, such as the ability to scale the amount of data in the DB effortlessly, automate routine, and a robust security system built into the database by default.
Is Oracle Database a good fit for you?
Oracle Database is a great product for those who value top notch performance, scalability, and endless possibilities when working with databases. Of course, such power, reliability and flexibility come with a price tag to match.
It is possible for a developer to set up an Oracle DB-engine on any existing software platform, and integrate it with a compatible cloud system. But the cost might be much higher than expected. Many features require additional licenses at an extra fee. This tends to discourage most independent developers from choosing Oracle as their solution. Additionally, it is harder to find web hosting that supports Oracle database installation and setup by default. In most cases, you will have to hire a professional to configure it, which would incur an extra expense.
How to create a database Copy link
Most hosting services will include access to an existing database that is automatically created upon renting the server. All that is required is to link the database and fill tables with the required information. It’s usually a good idea to find a web hosting service that offers a pre-installed database.
However, there are situations when you’ll want to create and set up the database yourself. Here’s how you can do that:
-
Choose the scripting language that will be used to operate the DB-engine (PHP, .NET, NodeJS, Python, etc.).
-
Gain SSH access to the server’s filesystem (where your app’s or site’s files are stored).
-
Configure your database using specific commands and queries unique to your chosen DB-engine. For example, in MySQL the command would look like this:
CREATE DATABASE name of databaseConfiguration settings, available parameters, and actions you must take in order to launch your DB depend on which technologies you choose.
How to host your database Copy link
This is a straightforward procedure. If you’ve ever hosted a website, you already know that it involves uploading the required files to the server hard drive. You can use the FTP protocol to do so.
The same goes for databases. Locate all of the necessary files and upload them to the server.
How to connect a database to web hosting (your app or website) Copy link
Once you’ve completed all of the necessary preparations, you can go one of two ways. Either set up everything manually, or entrust the task to a hosting provider such as Hostman, which gives new customers a free 7-day trial period to try all the functions, including the deploying and testing of databases.
If you want to connect a website to an existing database yourself, you should use the connect query for the Structured Query Language of your choice. In the case of MySQL, it would look something like this:
$connect = mysql_connect(localhost, username, password)Configuration settings, available parameters, and actions you must take in order to launch your DB depend on your chosen technologies.
Most people avoid getting into manual setup, as it is a rather complicated and cumbersome task.
The more practical route is to leave the task to a dedicated hosting provider that can offer you a hassle-free and professional setup, adhering to industry best practices.
For instance, Hostman allows you to connect popular DB-engines to your website or with just a few clicks. All you need to do is choose your DB-engine, select your hardware configuration, and click the "Deploy" button.
That’s all there is to it.
To conclude Copy link
At this point, you should have a basic understanding of what databases are and what they do, and the basic principles of a DB-engine’s functionality.
This is enough knowledge to get you started. But you should know that there’s a lot more to learn. Mastering databases is not for the faint of heart. It requires years of practice, trial and error, digesting a lot of documentation just to stay up to date with the latest technology.
Your choice of database depends on your skills, preferences and requirements. Here’s a “cheat sheet” to help you out when making your decision.
-
MySQL is a great DB-engine for those who want to launch an app or website as quickly as possible, without getting involved in complex processes, and without worrying about how databases work.
-
PostgreSQL is a product for webmasters who like MySQL but want to get a better-performing and more stable solution.
-
Oracle is an enterprise solution for massive businesses. It offers tons of features for specialists who want granular control of their DB-engine configurations.
-
MongoDB is a nice alternative for developers with experience in working with NoSQL databases. It is based on JSON-formatted files and is powerful enough to process large DBs.
-
Microsoft SQL Server is the solution of choice for MSFT fans who feel at home working within the Microsoft environment.
There are many DB-engines out there. The great news is that you can test many of them without having to host them manually.
How?
Just sign up for Hostman and choose the database you want to try out. There’s a whole selection of DBs ready to deploy as soon as you register.
Hostman is stable, practical, and free of charge for the first week of use. It’s the perfect platform for you to find the perfect database for your website or app.
Sign up today.