7 Data Analytics Trends for 2022 That You Need to Watch Out For
Over the past few years, data analytics has become a goldmine. The more data a company has, the more insight they have to make smarter decisions. With the data industry worth an estimated $274 billion in 2022, it’s no wonder big data is the driving force for the future.
The pandemic continues to drive business digital transformations. Applications have an improved capacity to interpret incoming data for its user. This means that the opportunities for business growth are endless.
Organizations embrace the cutting-edge data technology available to them. Data analytics continues to evolve, from big data to artificial intelligence (AI), data-driven models are in demand more than ever.
With the pandemic and its economic disruptions, businesses now realize they need to better use the data available to them. With data analytics traditionally used to assess ‘what happened?’ It is now used to predict ‘what will happen?’
With that in mind, let’s take a look at the top seven data analytics trends for 2022 and how they can benefit your business.
Smarter artificial intelligence Copy link
With the introduction of artificial intelligence (AI), organizations are experiencing a specialized change in business strategy. AI accelerates business decision making by automating processes that determine data analytics.
By developing training models and testing metrics in agile methodology, AI ensures rapid data insight without the need for data scientists. Organizations are utilizing AI algorithms to measure, predict, and interpret large amounts of data. Data refers to the market, customers, and online applications.
The pandemic and the rise of remote work have increased opportunities to track and measure data. Due to this rise in data availability, establishing a new data-driven culture was necessary. A culture that fuels investments via AI-based technologies produces intuitive data analytics.
AI systems work with both large and small data sets. The systems protect privacy, are adaptive, and provide a faster return on investment. The advancement of intuitive UIs in services such as metabase analytical services promotes accessibility and efficiency. Simply put, it’s never been easier to interpret data.
Edge computing Copy link
CTO of Kinetica, Nima Negahban, describes edge computing as ‘data analysis that takes place on a device in real-time.’ She goes on to say that ‘edge computing is about processing data locally, and cloud computing is about processing data in a data center or public cloud.’
Edge computing delivers data analytics technology closer to the physical asset. From wrist wearables to mobile traffic apps, worldwide spending on edge computing is expected to reach $176 billion in 2022.
To introduce edge computing into business systems, industries need to include IoT app development and other data transformation services.
By processing data storage closer to the devices that collect it, edge computing is more reliable. With real-time processing there is no issue of latency, it is also more cost-efficient than cloud-based storage.
Cloud-based data solutions Copy link
As data is being produced in large quantities, there will be an increasing shift towards cloud-based solutions. A database in the cloud involves labeling, cleaning, formatting, and collecting. It equates to a mammoth amount of storage for one location. This is where cloud-based platforms come into play.
The cloud opens the door for the next generation of data warehousing. With added accuracy and security in the form of an existing QA framework. New practices such as data mesh, data fabric, and Data Vault 2.0 have been intrinsically built via the cloud.
-
Data mesh - a holistic approach that allows data products connectivity across many domains. Enabling an information exchange without the need for storage.
-
Data fabric - architecture that enables data access in a distributed environment.
-
Data Vault 2.0 - based on the potential of the cloud, Data Vault 2.0 provides greater productivity. Driven by metadata for collaborative configuration and management of testing models.
Whilst a private cloud for your business can be costly, a hybrid cloud provides both private and public agility. A hybrid cloud approach offers companies the opportunity to switch between multiple cloud platforms. This is a more cost-effective approach for your business.
Data fabric Copy link
Due to our booming digital age, our interconnected ecosystem has become more complex than ever. Finding a solution to connect devices, applications, and data infrastructure formats is a constant challenge. Data fabric emerges as the solution.
Data fabric is a new answer to an old dilemma. With 73% of analytical data going unused, it has become essential for missing data to become discoverable. Data fabrics fuse data from internal silos and external data sources. This leads to the discovery of effective networks and business applications.
More companies are using data fabric architecture to produce more discoverable, pervasive, and reusable data from all environments. This includes private, public, and mulitcloud cloud systems.
Data fabric connects data from contrasting applications to identify new data relationships. It’s a form of referral software that enables rapid decision-making and cost-efficiency. Accelerating hybrid data integration ensures digital security and greater business value.
Data fabric is a technology that will become commonplace over the next few years.
Augmented analytics Copy link
Augmented analytics is a leading analytics concept that uses natural language processing (NLP), machine learning (ML), and AI. What used to be handled by a data scientist is now automated to offer economical data sharing and insight discovery.
Augmented analytics produces data integration from internal and external enterprises. Due to the specialist applications, the outcomes are more precise. NLP, ML, and AI ensure in-depth reports and forecasts, data processing, analytics, and visualization.
- Natural language processing - NLP provides computers with the ability to understand text and spoken words. It’s included in identifying patterns and trends in corporate operations. NLP is essential for tracking Twitter Analytics, understanding customer satisfaction, and smart assistants.
Machine learning - there is a growing use of data analytics and ML to predict what will happen in digital analytics and the best response to counter. Using ML to target specific customer needs, such as analyzing social media activity to determine what product they might buy.
- AI - AI helps make predictions more accurate, efficient, and cost-effective without the need for human intervention. AI will continue to be implemented in many different industries due to its unique possibilities.
 Machine learning - there is a growing use of data analytics and ML to predict what will happen in digital analytics and the best response to counter. Using ML to target specific customer needs, such as analyzing social media activity to determine what product they might buy.
Machine learning - there is a growing use of data analytics and ML to predict what will happen in digital analytics and the best response to counter. Using ML to target specific customer needs, such as analyzing social media activity to determine what product they might buy.With the introduction of all three, it has never been easier to measure, interpret, and predict results. Targeting specific customer behaviors reduces problems such as customers leaving their digital shopping cart abandoned and inefficient resources.
NLP, MI, and AI have the capabilities to assist business intelligence and aid business users.
Businesses are focussing on operational agility and resilience to recover from difficult market situations.
Automated machine learning Copy link
Applying ML models to real-world situations is known as automated machine learning (AutoML). ML is more user friendly when it is automated. It can create and deploy systems that even non-experts can master.
AutoML enhances monotonous workloads. Leaving human interaction free for more complemented questions (think of automation in call centers).
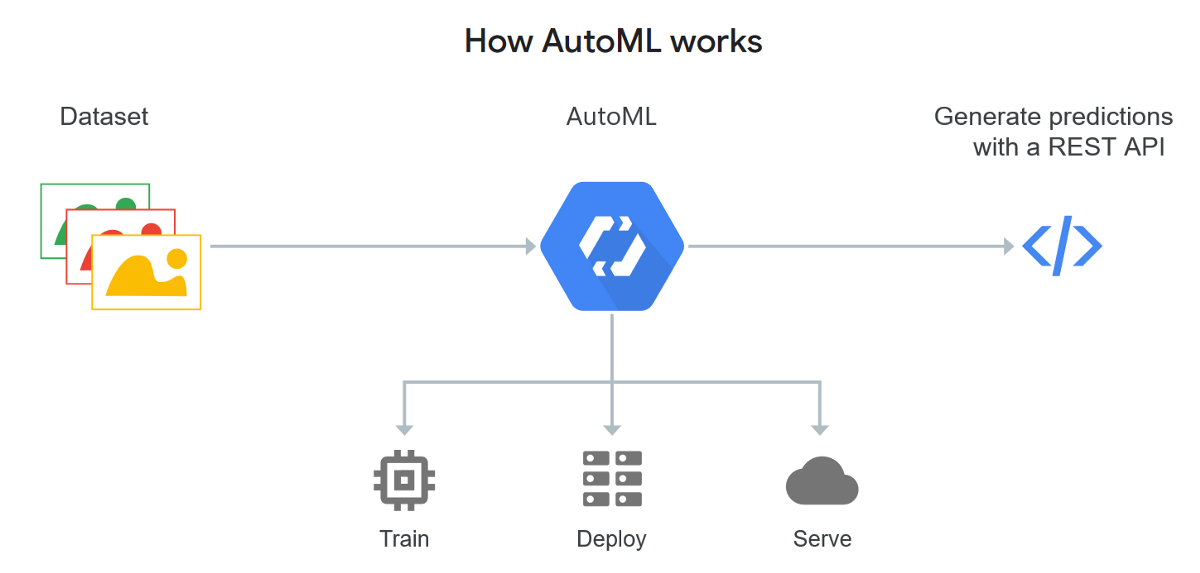
Businesses are counting on AutoML to increase data insight as end-users have direct access to these applications. As more users utilize this model, generating insight becomes easier and easier.
With the continuous release of machine learning tools, technical aspects of data science will become automated. This accelerates decision making by automating processes that data scientists would generally perform.
Much like how a mobile application is a must for small business development, AutoML is essential for rapid data insight. The more platforms that use it, the faster it becomes.
XOps Copy link
XOps has become an important fixture in business enterprise. It encompasses DataOps, ModelOps, AIOps, and PlatformOps, enabling automation of technology and processes. Making it a dominant combination of IT disciplines and strategic decision making when it comes to AI and machine learning (ML).
XOps data professionals can process defined goals that align with their business priorities. Its main focus is to enhance business operations as well as customer experience. Enhancing operations means enhanced security, which awards applications and offers advanced protection from DDoS attacks.
XOps strives to reduce duplication, ensuring more efficient and reliable data outcomes. Enabling XOps data and analytics allows the user to begin automation from the beginning rather than as an afterthought. It allows you to orchestrate your automating software in a way that meets measurable goals. Allowing more efficient data collection.
To cut a long story short Copy link
As data science continues to take the spotlight. Breakthroughs in future analytics continue to progress. Presently, data has never been more accessible, with companies able to collect, manage, analyze, and leverage data for future business intelligence.
Data analytics has become an essential part of business functionality. AI trends and data analysis provide valuable insight that improves business automation, accessibility, and intuition.
Organizations that successfully impose the above trends will be able to harness data strategically and efficiently. Tools such as automated machine learning and edge computing can improve customer algorithms via results and feedback.
Ensuring the process of data accumulation and evaluation is accessible, business actions have never been more necessary. Constantly improving analytics means businesses are constantly preparing for the future.
Author: Emily Rollwitz - Content Marketing Executive, Global App Testing
Emily Rollwitz is a Content Marketing Executive at Global App Testing, a remote and on-demand API automation testing tools company helping top app teams deliver high-quality software, anywhere in the world. She has 5 years of experience as a marketer, spearheading lead generation campaigns and events that propel top-notch brand performance. Handling marketing of various brands, Emily has also developed a great pulse in creating fresh and engaging content. She’s written for great websites like Airdroid and Shift4Shop. You can find her on LinkedIn.